
Web scraping with R
Share

[et_pb_section admin_label=”section”]
[et_pb_row admin_label=”row”]
[et_pb_column type=”4_4″][et_pb_text admin_label=”Text”]
Web scraping is the process of retrieving data from the web from websites. It can be useful to retrieve data for research purposes, technology watch or simply to create a data history for later analysis. Today I propose to guide you step by step to discover how to scrape information from the web with the Rvest package for R.
Webscraping with Rvest & Rstudio
The R package “rvest” is the reference package for web scraping with R. It contains a series of functions that make it easy to retrieve data from web sites. The following 8 functions should allow you to cover all your needs to read, analyze, extract and interact with data present in HTML documents, thus facilitating web scraping and information extraction from web sites.
Rvest Main functions
read_html(): This function reads and parses an HTML page from a URL or a local file, allowing exploration and extraction of information.html_nodes(): This function selects specific elements in an HTML document using CSS or XPath selectors.html_text(): This function extracts the text from selected HTML elements.html_attr(): This function extracts specific attributes from selected HTML elements.html_table(): This function extracts HTML tables and converts them into a data frame object.html_form(): This function extracts HTML forms from a document.submit_form(): This function submits an HTML form with specified data.html_session(): This function creates a web session for performing HTTP requests, maintaining a connection state, and preserving cookies between requests.
How to scrape with R & the Rvest package step by step
After installing the package with install.packages(“rvest”), open your browser and the page containing the data you want to extract and copy the url. We will first create an object to store this url, then we will read this url with the read_html() function.
url <- "http://www.mywebsite.com/my_page.html"
page <- read_html(url)
Explore the code of the page with your browser console
by right clicking on the page and then “inspect” you will open the console of your internet browser. From here, you will be able to locate the code of the different elements you want to extract from the page
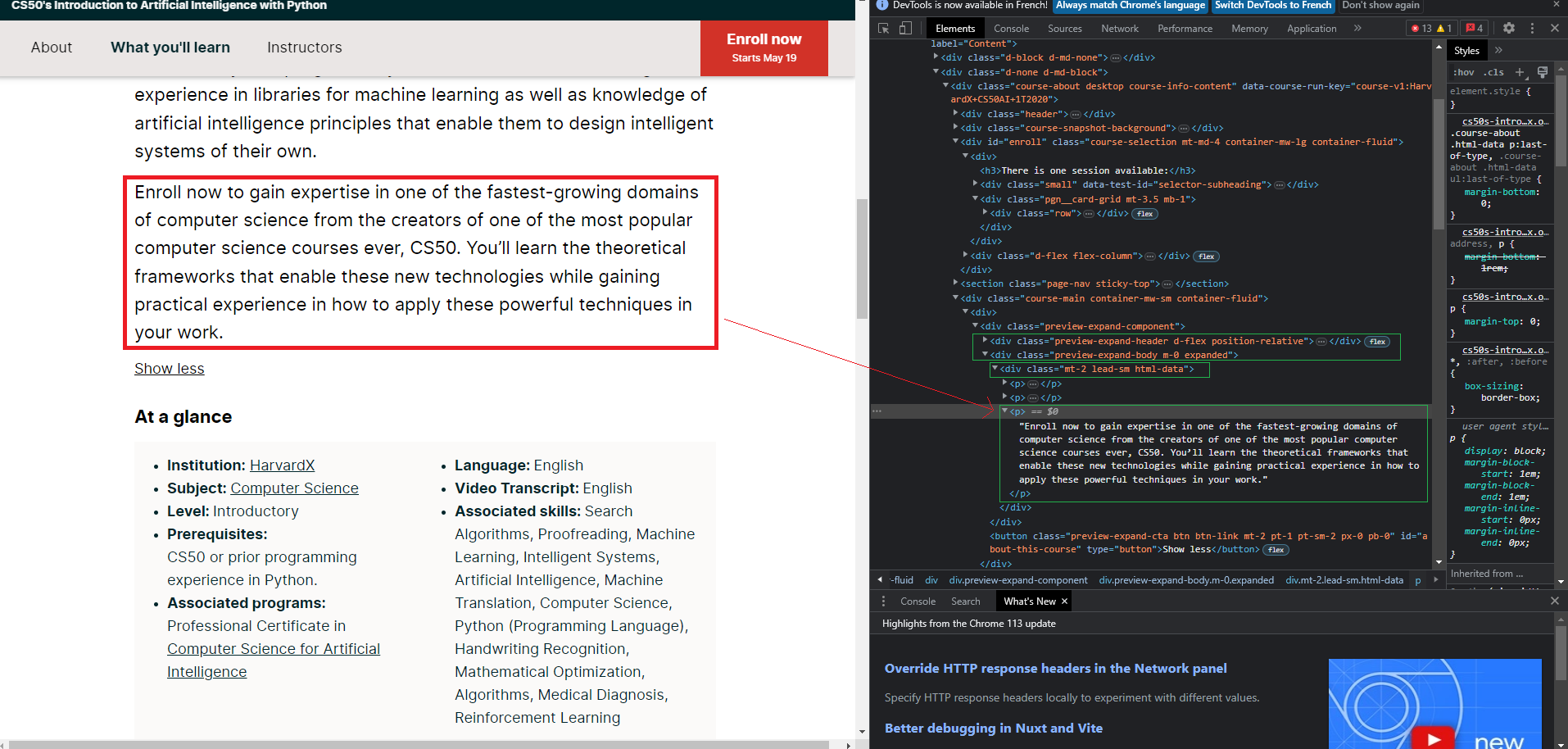
Select the data you want to retrieve using CSS selectors, the “div class=" for example or the XPath. To get the latter you can right click on the “copy -> copy xpath” code and it should look something like this: "//*[@id="main-content"]/div[2]/div/div[4]/div/div[1]/div[1]” These selectors allow you to specifically target the elements of the web page you want to retrieve.
To extract the data from the selectors, you need to use the html_nodes() function and convert the html content into plain text using html_text() as follows:
data <- html_nodes(page, "p") %>% html_text()
Example of web scraping of the elearning site edx :
We will now scrape a training on Edx called “Responsabilité societale des entreprises” (Corporate Social Responsibility)available here :
https://www.edx.org/professional-certificate/louvainx-responsabilite-societale-des-entreprises
#loading of librarieslibrary("rvest")
library("tidyverse")
# creation of url and page objects
url <- "https://www.edx.org/professional-certificate/louvainx-responsabilite-societale-des-entreprises"
page <- read_html(url)
# extraction of content elements title, university, course description, course module and price :
title <- html_nodes(page, xpath='//*[@id="main-content"]/div[2]/div/div/div/div[2]/div[1]/div') %>% html_text()
university <- html_nodes(page, "div.institution") %>% html_text()
learning <- html_nodes(page, xpath='//*[@id="main-content"]/div[3]/div/div[1]/div[2]/div[1]/ul/li') %>% html_text()
overview<- html_nodes(page, "div.overview-info") %>% html_text()
modules <- html_nodes(page, "#main-content > div.gradient-wrapper.program-body.container-mw-lg.container-fluid > div > div.program-section.pr-0.pl-0.container-mw-lg.container-fluid > div > div > div") %>% html_text()
price <- html_nodes(page, xpath='//*[@id="main-content"]/div[5]/div[1]') %>% html_text()
# Compilation of items in a list and export to a txt file
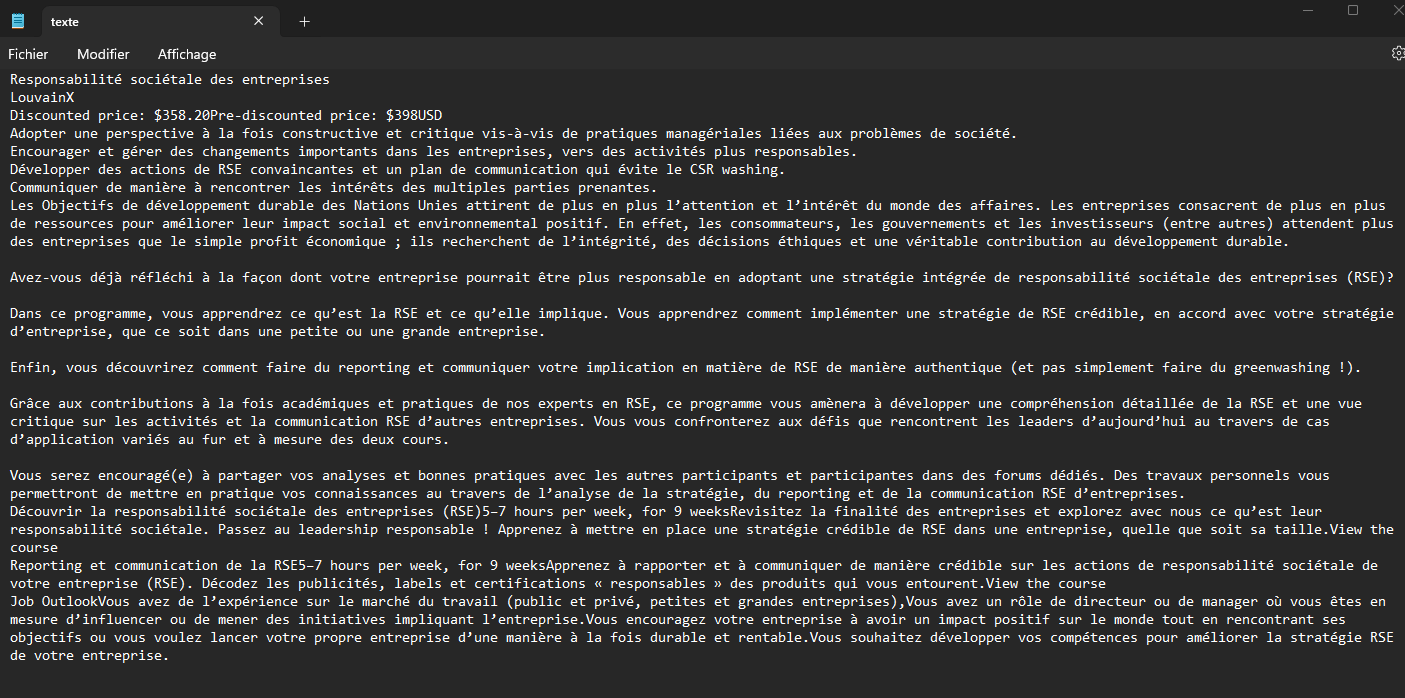
liste <- c(url, title, university, price, learning, overview, modules)
write(liste, "texte.txt")
the txt file should look like this:
This code performs the following steps:
- Loading the “rvest” package.
- Retrieve the web page using the “read_html” function.
- Selection of article titles using the “html_nodes” function and extraction of text using the “html_text” function.
- Selection of article links using the “html_nodes” function and extraction of the “href” attribute using the “html_attr” function.
- Creation of a list with all the items
- Creation of an export file of .txt elements
[/et_pb_text][/et_pb_column]
[/et_pb_row]
[/et_pb_section]


{kind=link}